At a Glance
As part of a competition organized by Städtische Werke AG in Kassel, the House of Energy e.V.
and the hessian.ai, Qnovi GmbH has developed an efficient and precise system for
forecasting the residual electricity demand of a municipal maintenance facility for the next day.
This required both a model to predict the electrical power produced by the facility's own photovoltaic system, as well as for the consumption within the facility. Whereas the solar power generated is primarily influenced by the weather, consumption forecasts are dominated by operational processes and human factors. For example, the system is able to correctly map the effects of bridge days or strike announcements on the electrical power required in the facility.
From the model predictions, it is possible to derive how much residual energy the energy supply company (EVU) must provide to the customer in the next 24 hours distributed over 15-minute intervals. This forecast can be used by the power supply company to make more targeted purchases on the EPEX day-ahead market.
This required both a model to predict the electrical power produced by the facility's own photovoltaic system, as well as for the consumption within the facility. Whereas the solar power generated is primarily influenced by the weather, consumption forecasts are dominated by operational processes and human factors. For example, the system is able to correctly map the effects of bridge days or strike announcements on the electrical power required in the facility.
From the model predictions, it is possible to derive how much residual energy the energy supply company (EVU) must provide to the customer in the next 24 hours distributed over 15-minute intervals. This forecast can be used by the power supply company to make more targeted purchases on the EPEX day-ahead market.
On 15.12.2022 the hessian.AI, Städtische Werke AG Kassel and the House of Energy e.V. launched a competition on Kaggle.
Here, data of a solar installation and an industrial facility were made available.
The goal was to predict the residual load, which can be calculated with the help of the produced photovoltaic power and the electrical consumption within the facility.
In total 22 teams participated in this competition and Qnovi GmbH reached 🥉 place.
In total 22 teams participated in this competition and Qnovi GmbH reached 🥉 place.
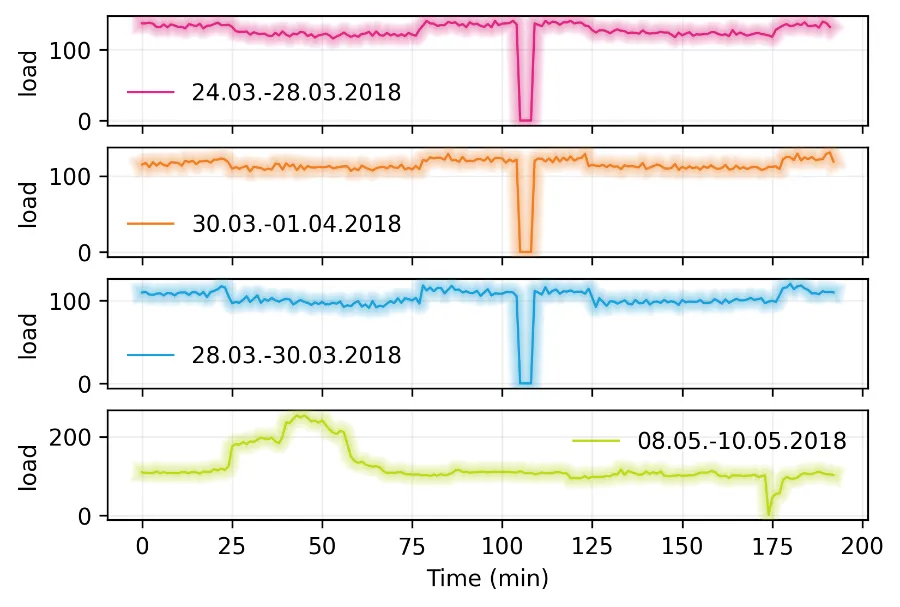
In a first step, we examined the data more closely and eliminated potential sources of problems.
These included various measurement errors where no load was measured or double values at the time changeover.
In addition, we gained a better understanding of the data and analyzed possible influencing quantities.
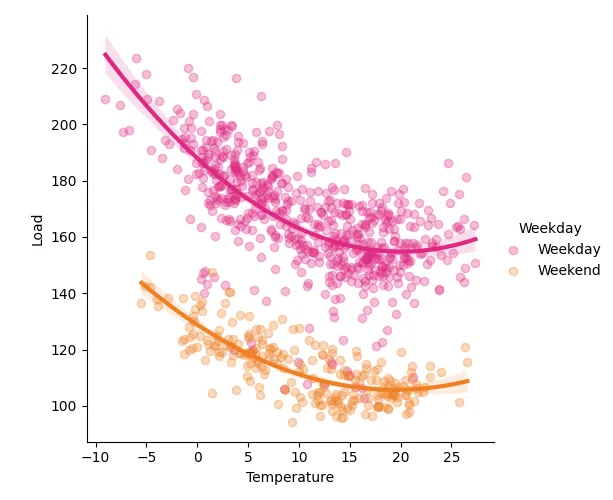
For example, load was highly dependent on the day of the week (weekday vs. weekend), seasonality, and ambient temperature. Some of the solar system data was relatively scattered and in some areas there were outliers where the radiation did not correlate with the power produced. Nevertheless, the generated power was dependent on sun radiation, ambient temperature but also on different weather events.
For example, load was highly dependent on the day of the week (weekday vs. weekend), seasonality, and ambient temperature. Some of the solar system data was relatively scattered and in some areas there were outliers where the radiation did not correlate with the power produced. Nevertheless, the generated power was dependent on sun radiation, ambient temperature but also on different weather events.
Once we had analyzed the various influencing variables, we had to make them available to the algorithm.
For this purpose, we had extended the already existing data by further features.
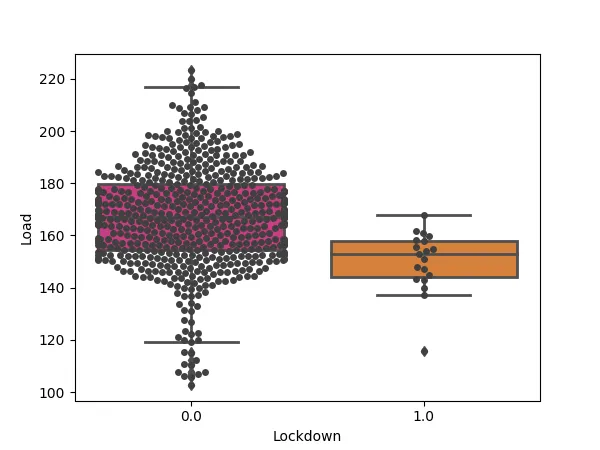
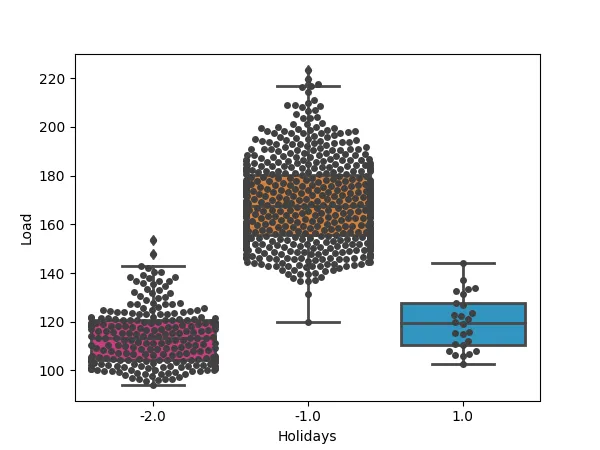
For example, the day of the week, the month, the year, or more complex contexts such as holidays or strikes were used for load forecasting.
Additional weather data from the German Meteorological Service (DWD) was used to forecast photovoltaic output. It was also investigated whether other weather radar data could be used. However, due to the unknown location of the installation, this could not be pursued further during the competition.
Additional weather data from the German Meteorological Service (DWD) was used to forecast photovoltaic output. It was also investigated whether other weather radar data could be used. However, due to the unknown location of the installation, this could not be pursued further during the competition.
The next step was to prepare the data so that it could be used for training.
On one hand, the data had to be split so that the prediction accuracy could be compared with an independent data set.
In addition, the data had to be divided into day-by-day blocks. This ensured that the algorithm could also learn a time context.
In addition, the data had to be divided into day-by-day blocks. This ensured that the algorithm could also learn a time context.
The training of the AI algorithm was done using the Tensorflow library and took between 8-12 minutes depending on the settings.
These short training durations result from the relatively small amount of data compared to other projects.
Since the competition was to achieve the best possible prediction accuracy, an automated optimization
of the algorithm's hyperparameters was performed using Ray Tune.
To keep track of the different networks, the ML-Flow library was used. This allowed different configurations to be traced and the best settings to be determined.
To keep track of the different networks, the ML-Flow library was used. This allowed different configurations to be traced and the best settings to be determined.
In order to ensure a reliable and accurate prediction, the algorithms were examined in more detail.
For this purpose, the accuracy was calculated on the basis of a validation data set,
and the influence of the different input variables was investigated.
In addition, the prediction in the time boundary areas was also tested, among other things.
The implementation of the algorithm was not part of the challenge.
In general, the algorithms can be connected to existing systems in various ways.
Thus, these can be executed on the cell phone (iOS/Android) and a microcontroller or even in the browser as well as on the PC.
For this purpose, a wide variety of interfaces are available via C, C++, Python, Swift, Java and Javascript.

Icons created by Freepik , Smashicons, Eucalyp - Flaticon